2021-09-16
To-Do
- 7시 기상
- 아침식사
- 오전운동 (어깨)
- 스파르탄 4일차, 상당히 일어나기 힘든 아침. 오늘도 쉐이크를 타먹고 헬스장으로 향했다. 이제 아침은 완연한 가을이다. 상당히 피곤했지만 상쾌한 아침이었다.
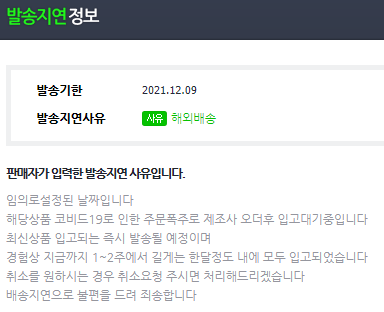
ps. 크레아틴 배송지연,,, 망할 코로나...
Today I Learned
1. SSR Vs. CSR
어제에 이어
그렇다면 jinja2와 같은 템플릿 언어는 왜 사용하는 것일까?
웹 페이지를 구성하는 방법은 크게 두가지가 있다.
우선, 서버에서 여차저차 쿵짝쿵짝을 통해 모든 것을 처리 한 뒤, 클라이언트의 브라우저에 정적으로 파일을 전송해주는 "Server Side Rendering (SSR)"
이와 반대로, 처음에 페이지가 렌더링 될 때 서버로부터 데이터가 없는 HTML, static 파일들만 받아오고, 이 후에 데이터를 받아서 클라이언트가 페이지를 직접 렌더링 하는 것, 모든 로직, 데이터 템플릿 및 라우팅은 서버가 아닌 클라이언트 에서 처리가 되는 것을 "Client side Rendering (CSR)"이라고 한다. 이는 "Single Page Application (SPA)"의 개념과 이어진다.
아주 옛날 90년대에는 거의 대부분의 웹이 Static Site였다. 서버에서 이미 HTML을 만들어 둔 뒤, 클라이언트가 요청하면 해당 HTML을 그대로 전송해주었다. 사용자가 다른 페이지로 넘어가면, 해당 페이지를 다시 한번 전부 업데이트를 해야했다.
점점 사용자가 많아지고, 수많은 요청을 처리하다보니 서버부하가 커지게 되면서 사용자 경험의 악화를 가져오게 되었다. 이때 등장한 기술이 Ajax이다.
HTML문서 전체가 아니라 JSON형식으로 서버에서 클라이언트가 필요한 정보만 가볍게 받아 올 수 있게 된다. 받아온 데이터는 JS를 이용하여 동적으로 HTML요소를 생성하고 이를 클라이언트의 페이지에 업데이트하면서 서버의 부하는 줄어들고, 사용자 경험을 개선할 수 있게 된다.
이렇게 CSR의 편리함을 경험한 개발자들은 SPA라는 개념을 고안하게 되는데, url이 바뀌더라도, HTML을 다시 내려받지 않는 것이다. 우리가 잘 알고있는, JavaScript의 React가 이를 지원한다.
사용자의 컴퓨터 성능이 대폭 개선되고 JavaScript도 표준화가 됨에 따라 React, Angular, Vue와 같은 프레임워크가 등장하고, CSR이 대세가 되었다.
하지만 CSR도 몇가지 문제점이 있다. 먼저 완성된 HTML을 받는 것이 아니기 때문에 사용자가 접속하고 완성된 페이지를 받아볼 때까지 시간이 소요된다. 다음으로 SEO(Search Engine Optimization)의 문제를 들 수 있다. 검색엔진이 웹 사이트의 HTML검색할 때, CSR의 HTML body는 텅 비어있으므로 검색을 원활히 수행하지 못한다.
이러한 문제로 인해 다시 SSR이 도입되게 된다. 우선 필요한 정보들을 담은 HTML을 구성하고, JS파일등과 함께 클라이언트 사이드로 전송한다. 이렇게 되면, 클라이언트는 바로 잘 만들어진 HTML문서를 볼 수 있게 된다. 이때 사용되는 템플릿 언어가 jinja2이다. 한번 렌더링 된 후 다시 변경될 가능성이 적은 웹 페이지는 이러한 SSR을 잘 활용한다면 훌륭한 사용자 경험을 제공할 수 있다.
하지만 SSR에는 여전히 Static Site의 Blinking, 서버 과부하 문제점이 남아있다. 추가적으로 CSR보다 적은 Stie Interaction도 문제점으로 볼 수 있고, 마지막으로 HTML은 받아왔지만, 아직 JS를 내려받아 렌더링 하지 못하여, 사용자가 HTML의 여러 태그를 클릭하여도 반응을 하지 않는 이슈가 발생할 수 있다.
2. BeautifulSoup Vs. Selenium
"빅데이터"라는 단어가 화두가 된 후 위의 두 단어도 자주 본 것 같다. 나는 처음에 Selenium 더 어렵고 BeautifulSoup의 상위 호환으로 이해하고 있었다.
(어림없는소리!)
위의 두 단어를 알아보기 전에 crawling과 scraping의 차이점을 간단히 알아보자.
- crawling
- 한국에서는 "크롤링"이라는 단어가 상당히 포괄적으로 쓰이고 있다. 사실 크롤링의 엄밀한 정의는 "자동화를 통해 웹 상에서 페이지들을 돌아다니며 분류/색인하고 업데이트된 부분을 찾는 등의 일을 하는 것"을 뜻한다. 즉 우리가 아는 크롤링의 정의와는 사뭇 다르다.
- scraping
- 스크래핑이 사실 우리가 아는 크롤링의 정의에 더 가깝다. "웹 페이지에서 우리가 원하는 부분의 데이터를 수집하는 것"
이제 BeautifulSoup과 Selenium에 대해 말해보자.
BeautifulSoup은 간단히 말해서, HTML을 parsing하는 역할을 한다. 아니, parsing은 또 뭔데??
사실 나도 parsing이라는 단어를 처음 듣고 그냥 "아는척"했다. 문맥상 대충 그럴 것 같았으니까... parsing은 쉽게 말해 "구문 분석"이다. 그냥 "분석"이라고 이해하면 될 것 같다. XML, HTML, JSON같은 데이터를 분석하여 원하는 정보를 얻어내는 것을 parsing이라고 이해하면 될 것 같다.
그래서, 엄밀히 말하면, BeautifulSoup은 크롤링이 아닌 parsing을 위한 라이브러리 되시겠다. requests와 같은 모듈을 통해 받아온 url에 담겨있는 HTML을 분석하여 원하는 정보를 뽑아내는 역할을 하는 것이다.
예시_
data = requests.get(url)
soup = BeautifulSoup(data, 'html.parser')
이렇게 만들어진 soup객체에서
soup.select("#frm > div > table > tbody > tr")와 같이 원하는 정보를 얻어낼 수 있다.
예상했듯, BeautifulSoup에는 치명적인 단점이 있다. url을 통해 HTML을 받아와 parsing하는 것이니, 당연하게도 CSR방식의 웹은 parsing 할 수 없다. 아니 parsing해봐야 얻어 낼 정보가 없다. 클라이언트의 서버를 거치지 않으니까!!
이러한 문제를 해결하는 것이 Selenium이다.
Selenium은 "자동화 테스트"에 사용되는 프레임워크이다. chromebrowser.exe를 사용하여 브라우저를 사용자의 pc에서 직접 실행하여 해당 브라우저를 자동으로 조작한다. 따라서 CSR방식의 웹 페이지도 parsing이 가능해진다.
예시_
driver = webdriver.Chrome('./chromedriver')
driver.get(url)
req = driver.page_source
soup = BeautifulSoup(req, 'html.parser')
위와 같이 BeautifulSoup과 같이 사용된다.
개발자 입장에서는 BeautifulSoup만을 이용하여 크롤링, 아니 스크래핑이 가능한 상황이 상당히 행복하다. 두방식의 속도차이 때문이다. 당연하겠지만 Selenium은 내 pc에서 직접 브라우저를 실행하여 js파일을 구동하기 때문에 실행속도가 어마어마하게 걸린다. 경험해본 결과 Selenium을 활용하여 동적 스크래핑을 진행했을 때, BeautifulSoup만을 이용한 스크래핑보다, 같은 양의 문서 기준 5배 이상의 시간이 걸렸다.
오늘은 웹 개발의 필수개념중 하나인, SSR과 CSR을 공부하고 추가적으로 BeautifulSoup과 Selenium 차이점도 내 언어로 정리해 보았다. 내일도 화이팅이다!!
'Sparta' 카테고리의 다른 글
| [Sparta] 06. 연휴끝..!.md (0) | 2021.09.23 |
|---|---|
| [Spatra] 05.백신접종 & 타임어택 테스트 .md (0) | 2021.09.17 |
| [Sparta] 03. html은 프로그래밍 언어가 아닙니다 (0) | 2021.09.15 |
| [Sparta] 02-3. 두번째날, 웹과 파이썬 (0) | 2021.09.15 |
| [Sparta] 02-2. 두번째날, 웹과 파이썬 (0) | 2021.09.14 |
